HashMap小结
本文最后更新于:2022年12月19日 晚上
HashMap小结
- HashMap是基于哈希表实现的,每一个元素是一个key-value对,其内部通过单链表解决冲突问题,具有自动扩容机制。且key-value可为null。
- HashMap是线程不安全的。
- HashMap 实现了Serializable接口,因此它支持序列化,实现了Cloneable接口,能被克隆。
- 在jdk1.8之前,HashMap采用数组+链表的储存方式。从jdk1.8开始,HashMap采用数组+链表/红黑树的储存方式。在阈值大于8且数组长度大于64时,链表会转换为红黑树的形式,以此提高HashMap的搜索效率。
- 当链表长度>64以及链表长度>8时,链表将转化为红黑树。当红黑树结点小于6时,再转换为链表。
1、HashMap的储存过程
首先来看一下HashMap的储存过程。
1 | |
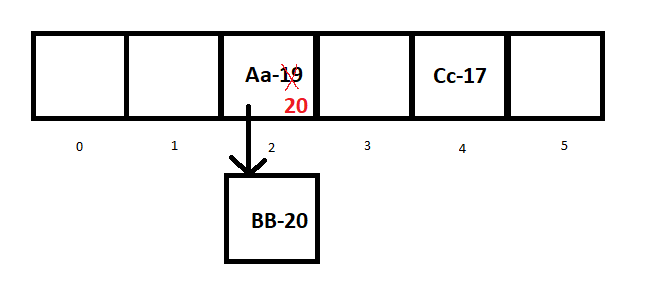
整个储存过程如下:
- 开辟数组空间(默认16)
- 通过位运算计算”Aa”的Hash值及对应的索引,存储Aa-19
- 同上,存储Cc-17
- 当存储BB时,计算发现索引已经储存了键值对,发生Hash碰撞,再调用euqals方法,计算发现不相等,所以便通过链表储存BB-20
- 最后Aa-20,计算HashCode以及euqals都相同,则覆盖先前的值。
问题1:HashMap底层通过什么方式计算Hash值?还有哪些方法可以用于计算Hash值?
HashMap底层采用位运算计算,还可以通过伪随机数和取余进行计算。(取余在计算机底层效率很低,所以不使用)
问题2:什么是Hash碰撞,如何解决?
不同的键计算Hash值索引相同即会产生Hash碰撞,通过链表+红黑树的方法解决。
2、HashMap的成员变量
2.1、默认容量
1 | |
HashMap默认容量为16,且容量必须是2的n次幂。即使赋值不是2的n次幂,在底层也会转换为2的n次幂。
举个栗子:
1 | |
在底层10会变为比它大的最小的2的n次幂:10->16。以此类推7->8。
问题3:为什么HashMap容量必须是2的n次幂?
为了减少Hash碰撞。
HashMap采用位运算:>>> ^ &计算Hash值。这个算法本质就是取模,hash%length,源码中进行了优化,使用hash&(length-1)进行计算,而hash%length等于hash&(length-1)的前提是数组长度为2的n次幂。
举个栗子:
数组长度为8
hash值: 3 00000011
length-1: 7 00000111,位运算结果:00000011,即索引为 3
hash值: 2 00000010
length-1: 7 00000110,位运算结果:00000011,即索引为 2
不会产生hash碰撞
数组长度为9
hash值: 3 00000011
length-1: 8 00001000,位运算结果:00000000,即索引为 0
hash值: 2 00000010
length-1: 8 00001000,位运算结果:00000000,即索引为 0
产生hash碰撞
2.2、负载因子
1 | |
HashMap负载因子为0.75
什么是负载因子?HashMap默认容量为16,当储存达到16*0.75=12时,便会执行扩容操作
threshold = capacity(默认长度16) * loadFactory(默认负载因子0.75)。这个值是是当前已经占用的数组长度的最大值,当size >= threshold时,便会执行扩容。
问题4:为什么负载因子设置为0.75?
如果负载因子过小,则数组利用率会降低,加载因子过大,链表数量又会过多。所以兼顾利用率和链表长度,0.75是一个衡量后比较平衡的值。
2.3、红黑树链表转换
1 | |
链表长度为8时:链表->红黑树,红黑树结点减少到6:红黑树->链表。
问题5:为什么链表长度为8时转换为红黑树?
根据泊松分布,HashMap中链表长度从0->8的概率是:
1 | |
因为红黑树占用的内存空间是链表的两倍,链表长度达到8已经是很小的概率,从而为了增加查找速度,才转换为红黑树。
红黑树平均查找复杂度是Log(n),如果长度为8,Log(8)=3,链表的平均查找复杂度是n/2,长度为8时,8/2=4;这才有转换为红黑树的必要。
2、HashMap的成员方法
2.1 put方法
put方法步骤分为以下几步:
首先通过hash值计算key应该映射到哪个索引;
如果索引没有hash碰撞,那么直接插入key-value;
如果出现碰撞,则需要进行处理:
a)已经使用红黑树,那么使用红黑树方法插入;
b)反之则使用链表插入,若达到临界值则转换为红黑树;
如果存在重复的key,那么则覆盖value;
如果size >= threshold,则执行扩容操作。
3、一些问题
问题6:HashMap和HashTable的区别
继承父类不同;
线程安全性不同,HashMap线程不安全,HashTable线程安全;
contains方法有区别,HashMap去掉了contains方法,改为containsKey和containsValue;
在HashMap中,key-value都支持null值,HashTable中则不支持;
1
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);HashMap通过将null值的key转换为0从而达到储存null值的key-value,而HashTable中则没有这个转换过程。
hash值不同。HashMap会重新计算hash值,HashTable则直接调用hashCode()方法;
问题7:HashMap如何实现线程安全?
- 使用ConcurrentHashMap
- 使用synchronizedMap()方法包装 HashMap,得到线程安全的Map,并在此Map上进行操作。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!