Cache Line和内存伪共享
本文最后更新于:2021年8月20日 晚上
1、抛砖引玉
首先看一个概念,摘自:LMAX Disruptor: High performance alternative to bounded queues for exchanging data between concurrent threads2.4
The way in which caching is used in modern processors is of immense importance to successful high performance operation. Such processors are enormously efficient at churning through data and instructions held in cache and yet, comparatively, are massively inefficient when a cache miss occurs.
Our hardware does not move memory around in bytes or words. For efficiency, caches are organised into cache-lines that are typically 32-256 bytes in size, the most common cache-line being 64 bytes. This is the level of granularity at which cache coherency protocols operate. This means that if two variables are in the same cache line, and they are written to by different threads, then they present the same problems of write contention as if they were a single variable. This is a concept know as “false sharing”. For high performance then, it is important to ensure that independent, but concurrently written, variables do not share the same cache-line if contention is to be minimised.
When accessing memory in a predictable manner CPUs are able to hide the latency cost of accessing main memory by predicting which memory is likely to be accessed next and pre-fetching it into the cache in the background. This only works if the processors can detect a pattern of access such as walking memory with a predictable “stride”. When iterating over the contents of an array the stride is predictable and so memory will be pre-fetched in cache lines, maximizing the efficiency of the access. Strides typically have to be less than 2048 bytes in either direction to be noticed by the processor. However, data structures like linked lists and trees tend to have nodes that are more widely distributed in memory with no predictable stride of access. The lack of a consistent pattern in memory constrains the ability of the system to pre-fetch cache-lines, resulting in main memory accesses which can be more than 2 orders of magnitude less efficient.
把重点内容翻译一下便是:
我们的硬件不会以字节为单位移动内存。为了提高效率,缓存被组装成大小为 32-256 字节的缓存行,最常见的缓存行是 64 字节。
如果不了解的话,可以先放在这,我们可以看一个简单的案例
2、小案例
1 | |
这是一个非常简单易懂的小程序,两个Case都开了两个线程,去递增一个类中不同的两个int变量,唯一的区别是,ObjectB中,有了好几个没有使用的变量,我们可以来看看程序的执行时间
| 循环次数 | Case1耗时(单位:秒) | Case2耗时(单位:秒) |
|---|---|---|
| 1M | 0.0273049 | 0.0101989 |
| 10M | 0.2711571 | 0.0717998 |
| 100M | 2.842166399 | 0.6833727 |
| 1000M | 29.0789099 | 6.7986955 |
很明显,在加了一些无关紧要的变量后,程序的整体性能提升了几倍,这就要引出伪共享这概念了
3、CPU缓存
伪共享的产生和CPU的缓存机制存在着非常紧密的关系,我们在这可以简单地了解一下CPU的缓存机制
CPU缓存是介于CPU和内存间的临时存储器,容量很小但是很快,因为CPU的处理速度远大于内存的速度,所以需要设置CPU缓存来加快CPU的处理。
CPU缓存分为三个级别:L1、L2、L3,越靠近CPU缓存的容量越小,但速度也越快,所以L1缓存最小,但速度最快,L2容量大一些且速度慢于L1。L3容量最大,读写速度最慢,但不同于L1和L2只能被单独一个CPU核独占,L3则是多核共享。
当CPU执行运算的时候,它先去L1查询所需的数据,然后去L2和L3,如果缓存中没有数据,则所需的数据就去内存中拿。流程越长,则耗费的时间就会越长,为了提高读写性能,则尽可能将数据保存在L1缓存中。
进入缓存的数据以缓存行(Cache Line)为单位存储的,缓存容量通常为64字节,并且它有效地引用主存地址中的一块地址,以一个long类型的数据为例,它的大小为8字节,即一个缓存行最多可以存储8个,而系统在将数据从内存读入缓存时,并不是只将所需数据读入到缓存中,而是将在同一缓存行的所有数据都读入到缓存中。
如下图所示,如果CPU1需要读取数据X,则系统读取到缓存中的数据除了X,还会一并将它相邻的数据Y和数据Z读入到缓存中,即使它们可能并不会用到。如果CPU1需要使用数据Y,则只需要从L1中读取数据即可,不需要再从内存中读取数据了,因此可以大大提高数据处理的性能。
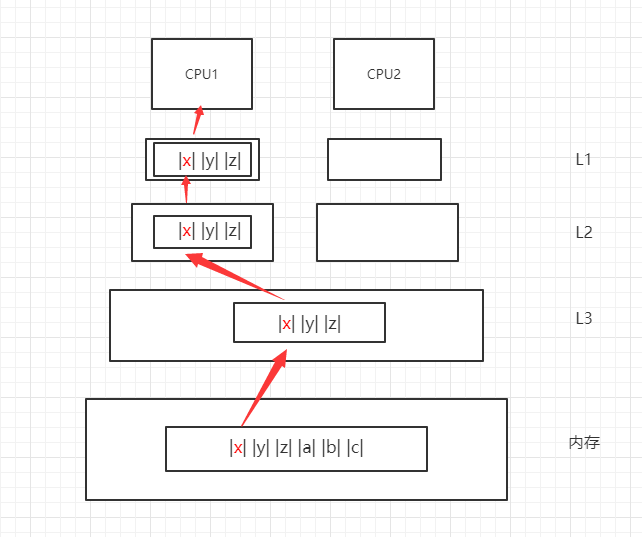
以上是CPU缓存的工作原理,在数据的读取阶段,并不会发生任何的问题,但是如果CPU需要向内存中数据时,由于多核多线程的缘故,需要考虑如何解决数据一致性的问题。
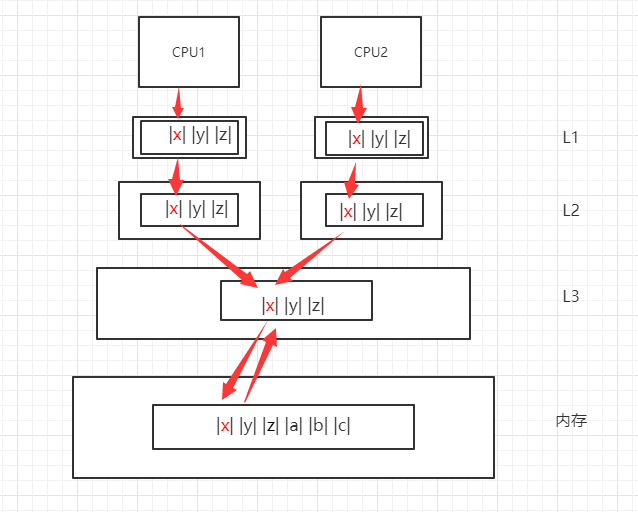
如下图所示,当CPU1读数据X的同时CPU2写数据X,如果没有一定的机制进行并发处理,则会发生数据一致性问题,导致脏数据的出现。
当前主流保持数据一致性的方式是使用MESI协议,它的具体原理不在本篇详述,感兴趣的读者可以查阅相关资料,它的主要功能通俗地讲就是,如果一个CPU修改了某个缓存行,那么缓存系统的其他的CPU认为该缓存行是脏数据而丢弃,并重新从内存中读取最新的缓存行。
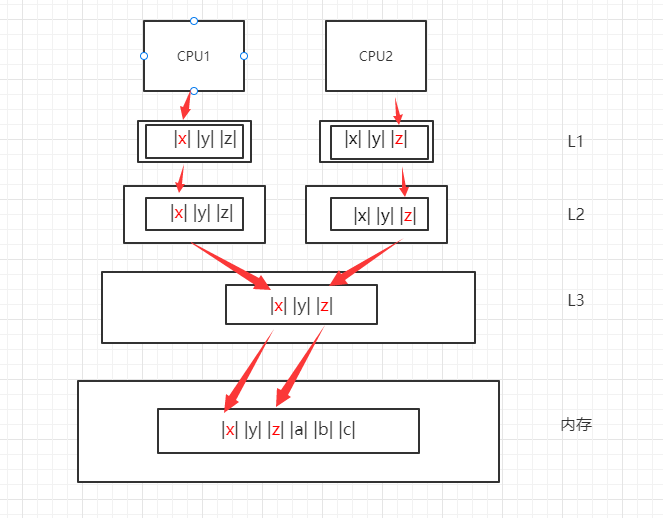
用下图的模型来解释,即当CPU修改数据X并写入到内存中后,则CPU1原先引用的缓存行将失效,需要重新从内存中读取最新的X数据。
4、伪共享的产生
以上就是CPU缓存系统的工作机制,而这个机制中就蕴藏着伪共享产生的温床。
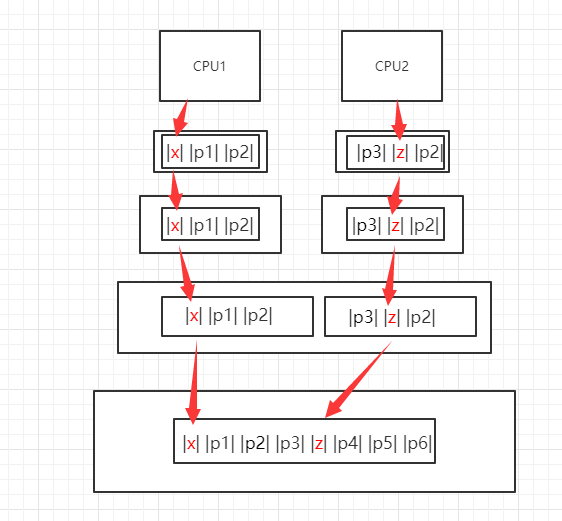
当前很多文献对伪共享的非标准定义为:缓存系统中是以缓存行为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,即称为伪共享(false sharing)。
如下图所示,CPU1需要修改的数据X和CPU2需要修改的数据Z在同一个缓存行中,若CPU1先行修改成功,则根据MESI协议,CPU2中L1和L2的缓存行数据将一起失效,缓存系统需要从内存中读取到一批最新的包含有数据Z的缓存行进行修改,这在无形中就会影响到系统的整体性能。
4、伪共享的避免
既然已经知道了伪共享产生的机制,那如何避免伪共享呢?
一种方式是在有必要的情况下,可以用单核CPU代替多核CPU来处理任务,根据上述的模型,单核模型则不需要考虑多核之间的数据一致性问题,也不会存在一个缓存行被多核读取的问题,因此也不会存在伪共享的问题。
另一种方式是采用缓存行主动填充,这也是多核CPU环境下的主流处理方式,它的原理就是在一条有效数据之后主动添加若干条无意义的数据,从而保证该条有效数据可以独占整个缓存行。如下图所示:
通过额外添加的数据,可以保证数据X和数据Z分隔在不同的缓存行中,即使出现缓存失效的状况,也可以做到相互之间互不影响,从而有效提高了系统的处理性能。回到一开始展示的代码,类ObjectB中那些无意义的long型数据其实就是利用上述的原理,作为缓存行的填充来挺高系统的处理效率。
4.2、java中的做法
在JDK1.8中,为了解决伪共享的问题,引入了一个注解:@Contended,加上注解,并设置JVM参数:-XX:-RestrictContended,即可避免伪共享:
1 | |
结果:
1 | |
5、防止伪共享的一点弊端
虽然避免伪共享对提高计算机处理性能有非常大的性能提升,但是该种技术当前并未成为主流,并且有许多人都是不了解或者未听说过该种技术。
原因就是因为它的弊端,使用避免伪共享技术主要会产生以下的弊端:
1、伪共享产生的条件苛刻且隐形。需要在多线程的环境,并且是对全局变量操作的过程中才会出现,并且伪共享的出现和代码的业务逻辑之间没有任何直接的关联,只能进入硬件层才能发现冲突产生的原因,但大部分开发者并不具备硬件开发或者调试的能力。
2、降低系统的性能。如果滥用缓存行填充技术,浪费CPU宝贵的cache资源,增加缓存系统读取内存的频率,从而降低了系统的性能。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!