下级系统网关的搭建
本文最后更新于:2023年11月11日 晚上
一、前言
1.1 网关是什么
通俗地讲,网关就是一个入口,在当前微服务盛行的情况下,随着各种服务的拆分,API的数量也成倍地增长,所以我们需要一个系统来对这些API进行管理,完成协议转换、鉴权、限流、监控等功能。
1.2 我需要什么
对于一个公司来说,大的服务网关通常已经搭建完毕,来负责公司各个服务的路由、鉴权,但是对于下级的服务来说,通常内部也需要一个”网关”的东西,接收来自外网的流量请求,然后进行协议转换、参数校验等自定义的行为,再发起内部HTTP/RPC请求,如图。
目前我们的框架承担着公司80%的推荐流量,每天上亿次的请求,现有的网关在可预见的未来,可能会成为数据链路上的短板,搭建一个新的网关系统也提上的日程。

二、网关的架构
首先可以看一下改进后的网关的架构
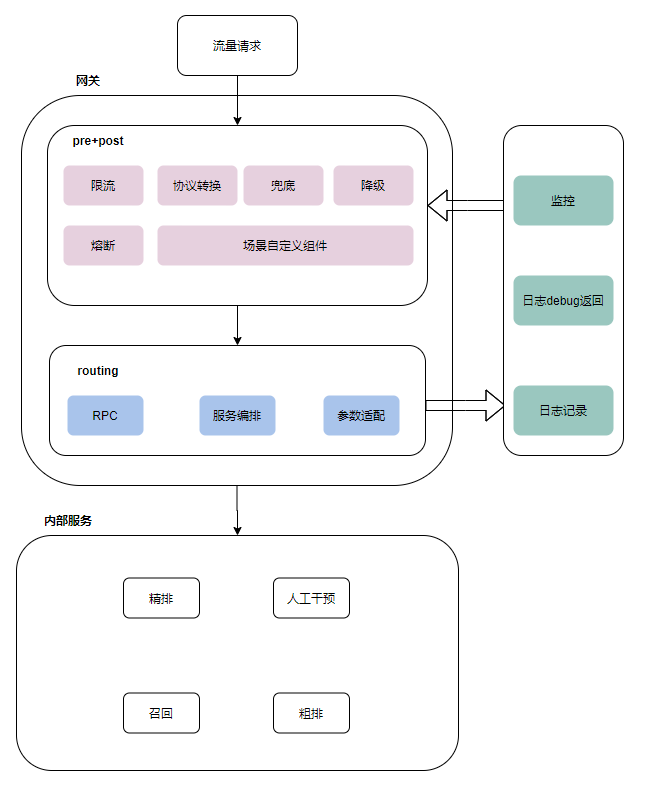
2.1 pre+post层
该层负责着流量的进入以及参数的返回,在流量进入后,会进行协议的转换,来适配下游服务。
熔断、限流、降级等都是网关的基础功能,不做赘述。
对于推荐系统来说,存在着非常多的场景:首页推荐、社区推荐、交易单商品推荐…,不同的推荐场景通常由不同的算法、工程同学完成,内部也存在着不同的逻辑。在请求进入系统后,网关会根据不同的场景选择相应的场景自定义组件,来对请求参数做个性化的处理。
同时,对于一个推荐系统的网关来说,兜底也是一个重要的功能。目前的网关可以根据场景配置进行前置兜底:对请求转发、直接兜底返回,以及请求流程的后置兜底:返回参数为空,兜底精华池或进行二次请求兜底。
兜底虽然是一个重要的功能,但是对于算法同学来说,这里面的逻辑是不可见的,所以目前网关中的兜底避免了比较复杂的机制(手动配置兜底返回等功能),只做了一些简单的工作。
2.2 routing层
在目前的推荐服务中,已经全部迁移到了dubbo,弃用了以前以feign为基础的rpc,所以在routing的阶段无需考虑一些协议的转换。
对于一个路由,主要的工作还是请求的转发、灰度、压测等功能。
为了方便链路的追踪、减少机器的压力,目前我们不同场景都对应着不同的集群,比如:场景A的流量会到集群A下的10台机器,场景B的流量会到集群B下的10台机器以及集群D下的8台机器。通过路由的判断,来分配这些请求的转发。
当然,仅有这样的分配是不够的,在大多数情况下,我们都有灰度、压测的需求,对于网关来说,还需要隔离这些请求,来防止影响线上健康的请求流量。除了上述的场景到机器的映射,这些不同的流量也会有不同的特征标签,routing层会根据这些标签,来判断是否为灰度、压测请求,来进行集群、机器的分配。同时,搭配自由的配置中心,完成线上的实时配置。
2.2.1 服务隔离

2.2.2 可灰度,可压测

2.3 日志系统
目前的系统是基于opentracing的全链路追踪,同时同步日志到阿里的SLS。除此之外,方便线上debug,在内网环境白名单的请求也会直接收集日志,并将推荐全链路日志返回,避免了拿到traceId再到SLS上去查询的麻烦操作。
2.4 监控报警
得益于公司完善的基架服务,监控以及报警都不需要下级的服务操心,直接接入基架组完成的监控以及报警系统并配置即可。本人也对监控报警了解不多,在此不做叙述。
三、其他
为了适配未来推荐系统的演进升级,本版网关是目前推荐架构下的第一次整合重构,因为开发人员并不多(设计和编写基本上都是本人完成TAT),所以还存在很多提升的空间,比如高可用,虽然目前整体服务的QPS已经达到了一个较高的值,但是保守的机器分配带来了低的单机QPS,单机的压力并不大,目前也不会遇到机器瓶颈。可能在QPS持续增加的未来,以及成本考虑,会开始考虑高可用的问题。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!